05 - Exploitation des données à partir d'une base de données
Une fois cette première phase réalisée, Python sera utilisé pour une deuxième phase d'analyse, l'exploitation et le rendu de la donnée.
- Au sein Microsoft Windows
- j’opterai pour SQL Server 2017 Express Edition comme système de base de données
- et SQL Server Management Studio (SSMS) pour l’administrer et l’interroger.
- Au sein d’un environnement Linux ou Mac OS
- j’opterai pour une base de données PostgreSQL
- et pgAdmin 4 pour l’administrer et l’interroger.
Exemple sous Windows
Installation de Microsoft SQL Server et SSMS
Télécharger SQL Server 2017 Express Edition.
Lancez l’exécutable et suivez les instructions d’installation.
Suite à cette installation votre ordinateur aura besoin de redémarrer.
Une fois redémarré, dans la même langue que votre installation SQL Server téléchargez et installez SQL Server Management Studio.
Une fois installé, ouvrez SQL Server Management Studio (menu Démarrer > Microsoft SQL Server Tools 17 > Microsoft SQL Server Management Studio).
Une instance de Microsoft SQL Server Express devrait automatiquement être détectée et proposée à la connexion (dans le cas contraire Nom du serveur > Parcourir… > Moteur de base de données > DESKTOP-XXXXX).
Cliquez sur Connexion.
Importation des données en base de données
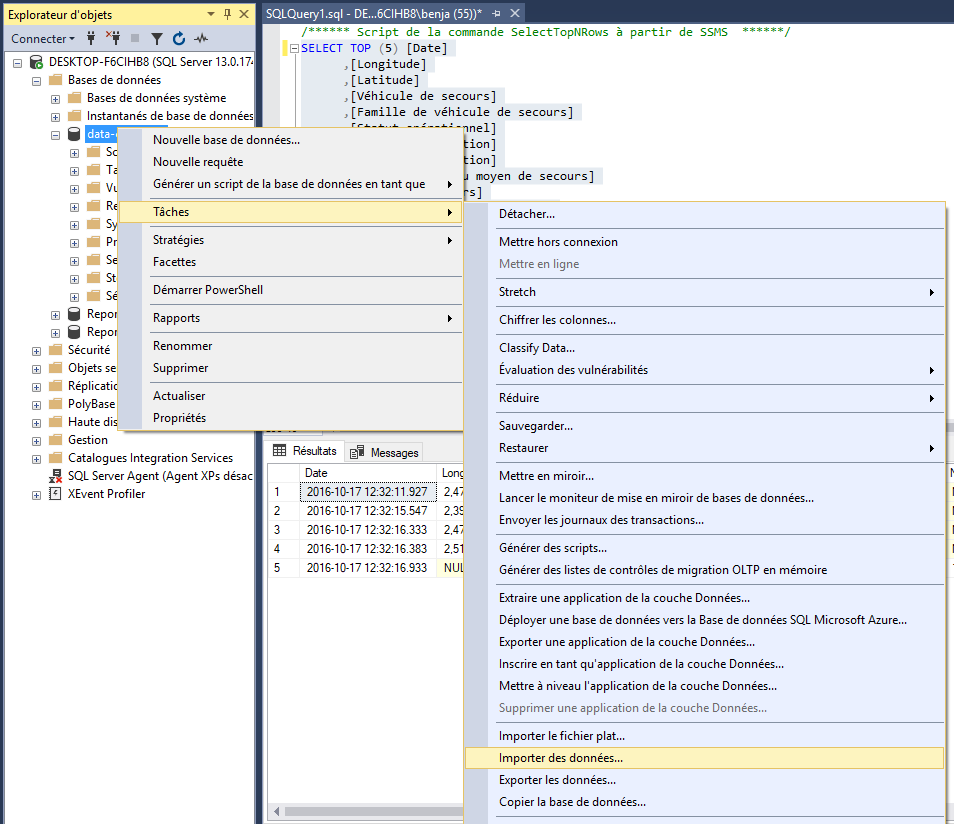
Créez une nouvelle base de données depuis l’Explorateur d’objets en faisant un clic droit sur le dossier Base de données.
Donnez lui un nom. et cliquez sur OK.
Faites un clic droit sur votre nouvelle base de données > Tâches > Importer des données…
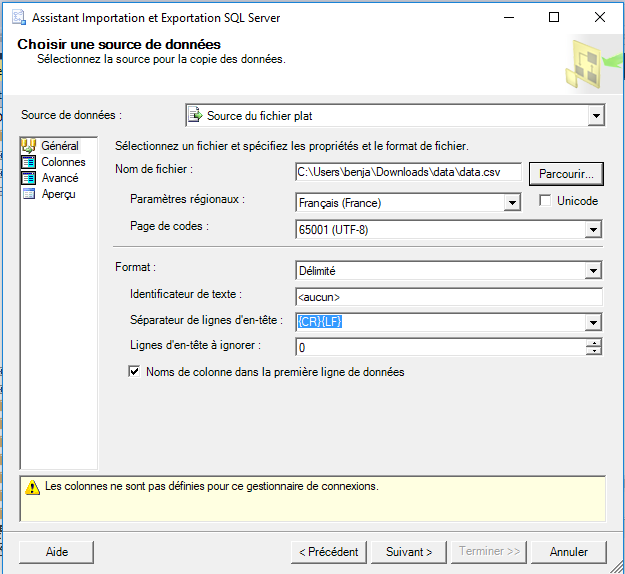
Sélectionnez pour Source de données : Source du fichier plat.
Suivant
Comme nom de fichier, allez chercher via le bouton Parcourir… le fichier data.csv (sélectionnez le format de Fichiers CSV) préalablement téléchargé et décompressé.
Ouvrir
Assurez-vous que le champ Page de codes ait bien la valeur : 65001 (UTF-8).
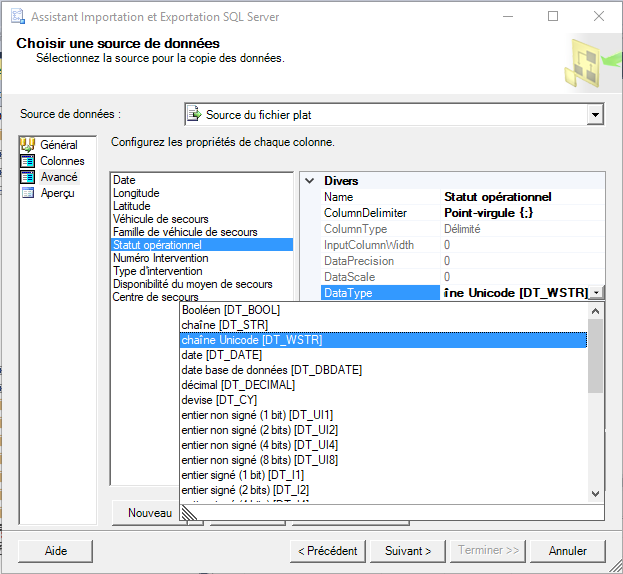
Via l’onglet Avancé, modifiez uniquement le DataType de la colonne Statut opérationnel en chaîne Unicode [DT_WSTR].
Suivant
Destination : SQL Server Native Client 11.0
Suivant
Cliquez sur Modifier les mappages….
Modifiez le type de la colonne Statut opérationnel en nvarchar.
OK
Suivant
Terminer
Dans l’Explorateur d’objets, suite un dans l’Explorateur d’objets sur le nom de la base de données > Actualiser vous devriez voir apparaitre votre table : dbo.data.
Vous pouvez y vérifier les données par un clic droit sur le nom de la table > Sélectionner les 1000 première lignes.
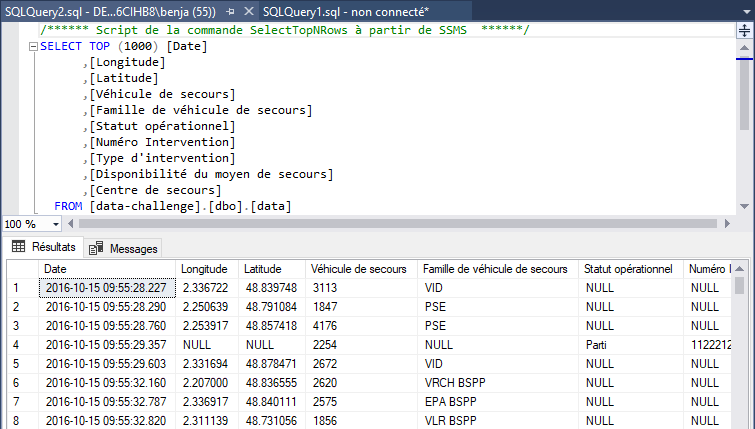
Nos données ont bien été chargées mais les types ne sont pas optimaux.
Nous allons donc créer une nouvelle table bénéficiant des typages adaptés.
Faites un clic droit sur votre table > Générer un script de la table en tant que > CREATE To > Nouvelle fenêtre d’éditeur de requête.
Et modifiez ce dernier de la manière suivante (ici un shéma dédié a été créé).
USE [data-challenge]
GO
/****** Object: Table [dbo].[data] Script Date: 15/12/2018 10:25:00 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE SCHEMA BSPP
GO
CREATE TABLE [BSPP].[data](
[Date] [Datetime] NULL,
[Longitude] float NULL,
[Latitude] float NULL,
[Véhicule de secours] int NULL,
[Famille de véhicule de secours] [varchar](50) NULL,
[Statut opérationnel] [nvarchar](50) NULL,
[Numéro Intervention] int NULL,
[Type d'intervention] [varchar](50) NULL,
[Disponibilité du moyen de secours] bit NULL,
[Centre de secours] int NULL
) ON [PRIMARY]
GO
Insérez à votre nouvelle table les données correctement formatées.
SET DATEFORMAT ymd
INSERT INTO [BSPP].[data]
SELECT CONVERT(datetime, [Date], 121)
,IIF([Longitude] NOT LIKE 'NULL', CAST([Longitude] As float), NULL)
,IIF([Latitude] NOT LIKE 'NULL', CAST([Latitude] As float), NULL)
,IIF([Véhicule de secours] NOT LIKE 'NULL', CAST([Véhicule de secours] As INT), NULL)
,IIF([Famille de véhicule de secours] NOT LIKE 'NULL', [Famille de véhicule de secours], NULL)
,IIF([Statut opérationnel] NOT LIKE 'NULL', [Statut opérationnel], NULL)
,IIF([Numéro Intervention] NOT LIKE 'NULL', CAST([Numéro Intervention] As INT), NULL)
,IIF([Type d'intervention] NOT LIKE 'NULL', [Type d'intervention], NULL) As [Type d'intervention]
,IIF([Disponibilité du moyen de secours] NOT LIKE 'NULL', CAST([Disponibilité du moyen de secours] AS BIT), NULL)
,IIF([Centre de secours] NOT LIKE 'NULL', CAST([Centre de secours] AS INT), NULL)
FROM [data-challenge].[dbo].[data]
Vous pouvez désormais manipuler de manière optimale au sein de SQL Server Management Studio.
Interrogation de SQL Server à partir d’un Jupyter Notebook
Une fois votre première phase d’analyse et de manipulation au sein de SQL Server Management Studio réalisée, vous voudrez pouvoir requêter votre base de données Microsoft SQL Server à partir du Jupyter Notebook.
Pour interroger SQL Server en Python vous pouvez utiliser le package pymmsql (ce package distribué sous conda-forge n’est destiné qu’aux plateformes linux-64 et osx-64, optez donc pour celui distribué par anaconda).
conda install -c anaconda pymssql
Pour exécuter très simplement des requêtes SQL au sein d’un Jupyter Notebook vous pouvez utiliser le package ipython-sql.
conda install -c conda-forge ipython-sql
Dorénavant au sein d’un Jupyter Notebook, vous pouvez saisir des requêtes SQL de la manière suivante :
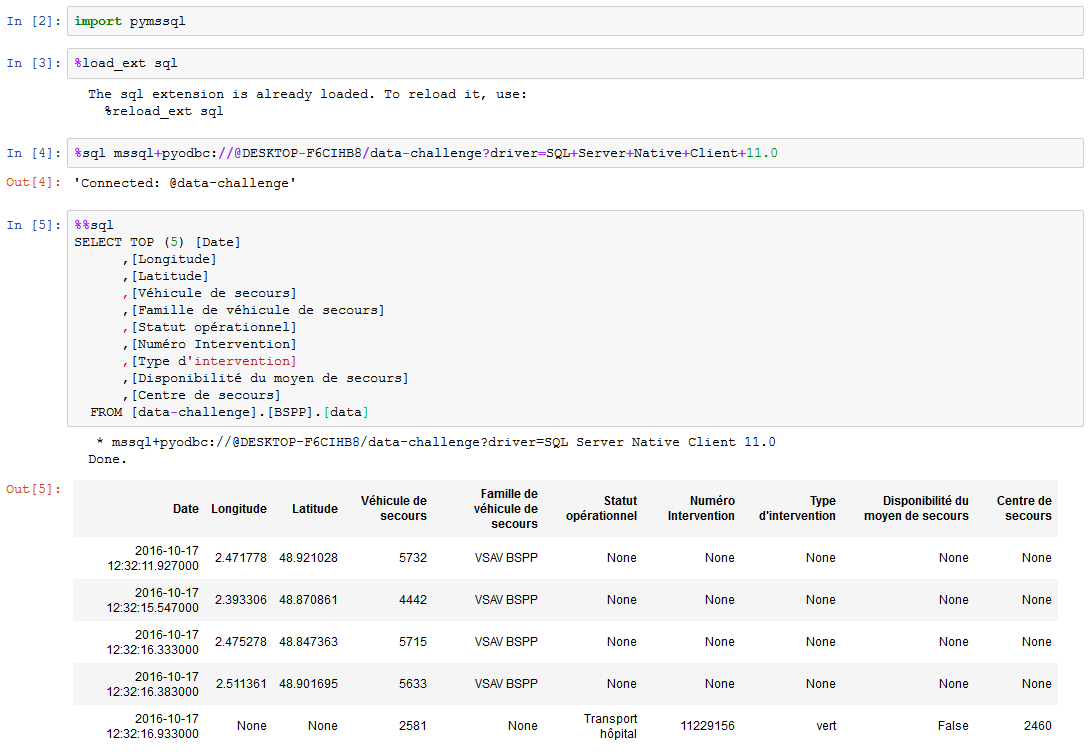
Chaînes de connexion
- sans identifiants
%sql mssql+pyodbc://@serveur/base_de_donnees?driver=SQL+Server+Native+Client+11.0 - avec identifiants
%sql mssql+pyodbc://login_utilisateur:mot_de_passe@serveur/base_de_donnees?driver=SQL+Server+Native+Client+11.0