05 - Using data from a database
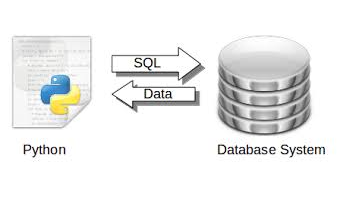
Once this first phase is done, Python will be used in a second phase to continue the analysis and data exploitation and data rendering activities.
- Within a Microsoft Windows environment
- I will opt for SQL Server 2017 Express Edition as a database system
- and SQL Server Management Studio (SSMS) to manage and query it.
- Within a Linux or Mac OS environment
- I will opt for a PostgreSQL database
- and pgAdmin 4 to manage and query it.
Within a Microsoft Windows environment
Microsoft SQL Server and SSMS installation
Download SQL Server 2017 Express Edition.
Launch the executable and follow the installation instructions.
Following this installation your computer will need to restart.
Once restarted, in the same language as your SQL Server installation download and install SQL Server Management Studio.
Once installed, open SQL Server Management Studio (Start menu > Microsoft SQL Server Tools 17 > Microsoft SQL Server Management Studio).
An instance of Microsoft SQL Server Express should automatically be detected and offered at login (otherwise Server name > Browse… > Database Engine > DESKTOP-XXXXX).
Click on Connect.
Importing data into a database
Create a new database from the Object Explorer window by right-clicking on the Database folder.
Give him a name. and click OK.
Right click on your new database > Tasks > Import data…
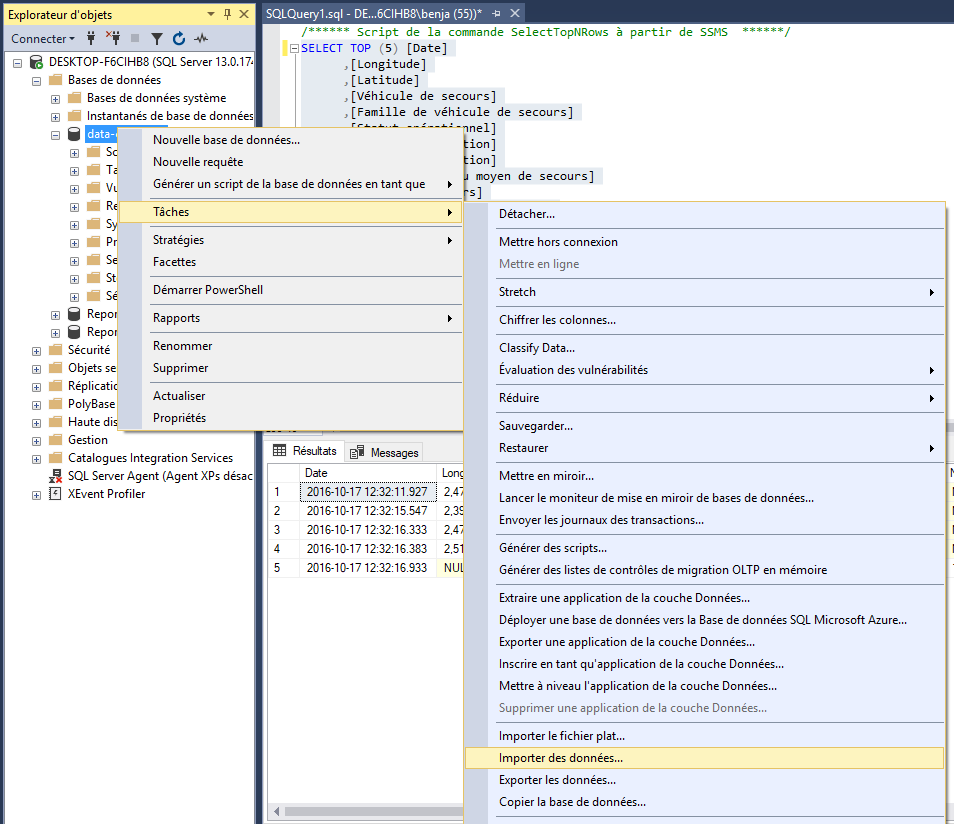
Select for Data Source: Flat File Source.
Next
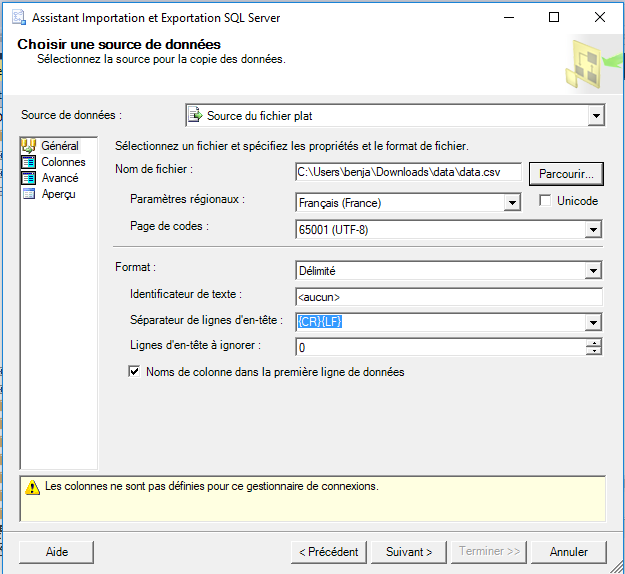
As file name, browse through the Parcourir… button the data.csv file (select the CSV file format) previously downloaded and unzipped.
Open
Make sure the Code Page field is set to 65001 (UTF-8).
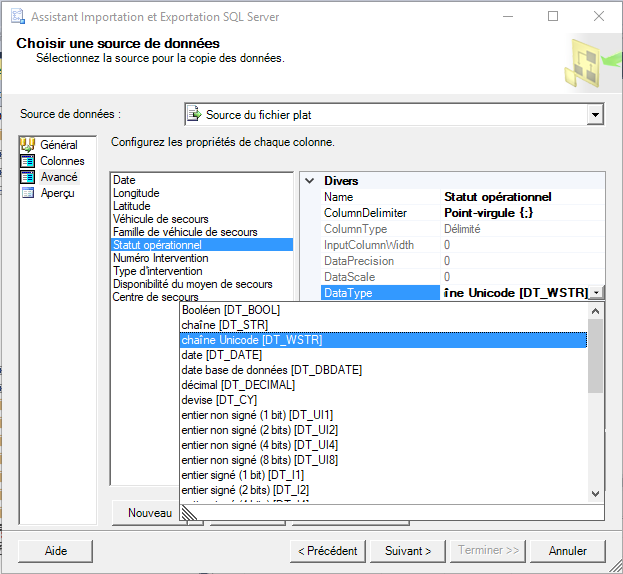
Via the Avanced tab, modify only the DataType of the Unicode String Statut opérationnel column [DT_WSTR].
Next
Destination : SQL Server Native Client 11.0
Next
Click Edit mappings….
Change the type of the Statut opérationnel to nvarchar.
OK
Next
Finish
In the Object Explorer window, with a right click on the database name > Refresh you should see your table: dbo.data.
Here you can check the data by right clicking on the table name > Select first 1000 rows.
Our data has been loaded but the types are not optimal.
We will therefore create a new table with the correct data types.
Right-click on your table > Generate Table Script As > CREATE To > New Query Editor Window.
And modify this code in the following way (here a dedicated diagram has been created).
USE [data-challenge]
GO
/****** Object: Table [dbo].[data] Script Date: 15/12/2018 10:25:00 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE SCHEMA BSPP
GO
CREATE TABLE [BSPP].[data](
[Date] [Datetime] NULL,
[Longitude] float NULL,
[Latitude] float NULL,
[Véhicule de secours] int NULL,
[Famille de véhicule de secours] [varchar](50) NULL,
[Statut opérationnel] [nvarchar](50) NULL,
[Numéro Intervention] int NULL,
[Type d'intervention] [varchar](50) NULL,
[Disponibilité du moyen de secours] bit NULL,
[Centre de secours] int NULL
) ON [PRIMARY]
GO
Insert the correctly formatted data to your new table.
SET DATEFORMAT ymd
INSERT INTO [BSPP].[data]
SELECT CONVERT(datetime, [Date], 121)
,IIF([Longitude] NOT LIKE 'NULL', CAST([Longitude] As float), NULL)
,IIF([Latitude] NOT LIKE 'NULL', CAST([Latitude] As float), NULL)
,IIF([Véhicule de secours] NOT LIKE 'NULL', CAST([Véhicule de secours] As INT), NULL)
,IIF([Famille de véhicule de secours] NOT LIKE 'NULL', [Famille de véhicule de secours], NULL)
,IIF([Statut opérationnel] NOT LIKE 'NULL', [Statut opérationnel], NULL)
,IIF([Numéro Intervention] NOT LIKE 'NULL', CAST([Numéro Intervention] As INT), NULL)
,IIF([Type d'intervention] NOT LIKE 'NULL', [Type d'intervention], NULL) As [Type d'intervention]
,IIF([Disponibilité du moyen de secours] NOT LIKE 'NULL', CAST([Disponibilité du moyen de secours] AS BIT), NULL)
,IIF([Centre de secours] NOT LIKE 'NULL', CAST([Centre de secours] AS INT), NULL)
FROM [data-challenge].[dbo].[data]
Querying SQL Server from a Jupyter Notebook
Once you have completed the first phase of your data analysis and manipulation within SQL Server Management Studio, you will want to be able to query the Microsoft SQL Server database from the Jupyter Notebook.
To query SQL Server in Python you can use the package pymmsql (this package distributed under conda-forge is only for linux-64 and osx-64, so choose the one distributed by anaconda).
conda install -c anaconda pymssql
To directly execute row SQL queries within a Jupyter Notebook you can use the ipython-sql package.
conda install -c conda-forge ipython-sql
From now on in a Jupyter Notebook, you can enter SQL queries as follows:
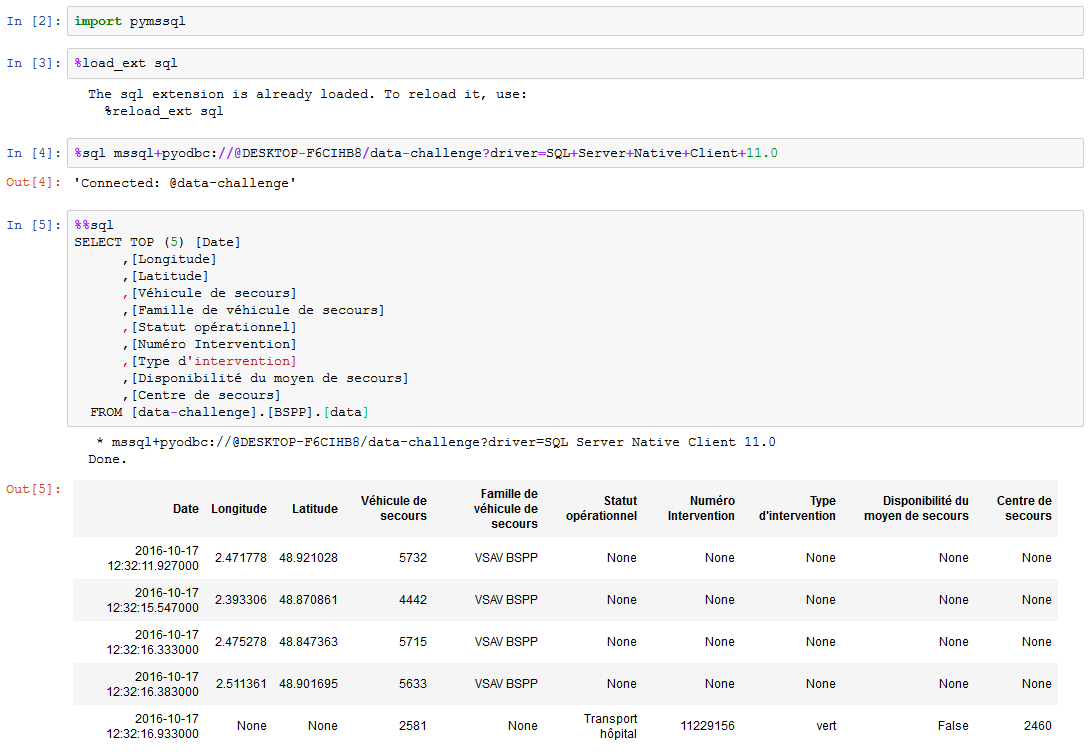
Connection strings
- without identifiers
%sql mssql+pyodbc://@serveur/base_de_donnees?driver=SQL+Server+Native+Client+11.0 - avec identifiers
%sql mssql+pyodbc://login_utilisateur:mot_de_passe@serveur/base_de_donnees?driver=SQL+Server+Native+Client+11.0